We argued before that a programmer’s real value is in constraint design, in defining the boundaries that AI agents operate within. But there’s a practical problem with that thesis: how do you design constraints for something you can’t observe?
Every developer using Claude Code, Gemini CLI, or Codex generates data as a side effect. Session logs, token counts, tool invocations, model switches, cache hits. It all sits in scattered JSONL files on your machine, and nobody reads it. Those are the behavioural traces of your AI tools, going to waste.
So we built vibe-usage.
What it is
vibe-usage is a single Rust binary. No database, no cloud service, no account. Install it, run vibe-usage sync to collect your local AI tool logs, run vibe-usage serve to open a dashboard. That’s it.
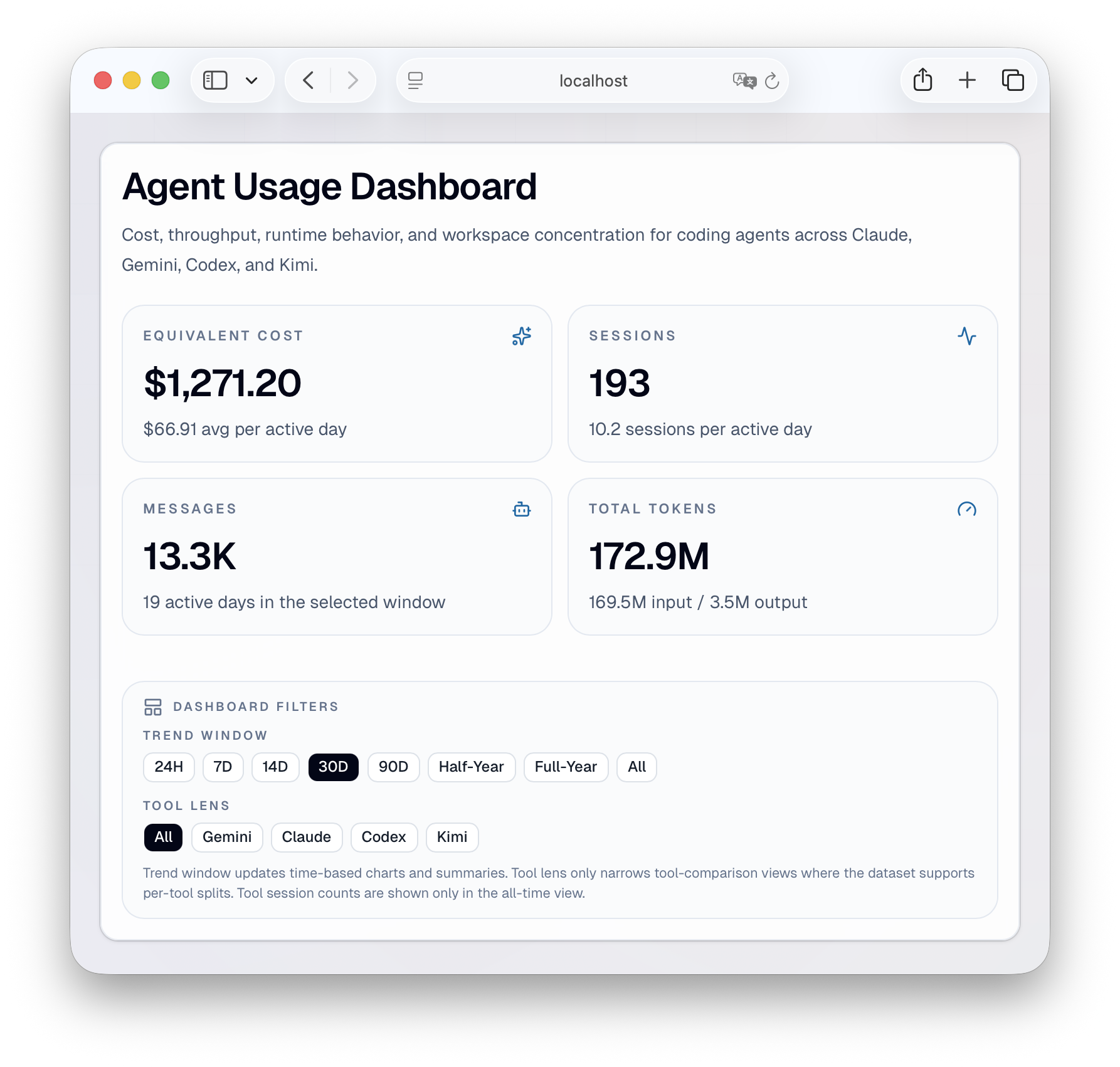
It supports three tools today: Claude Code, Gemini CLI, and OpenAI Codex. It parses their native log formats, normalises them into a common schema, and serves a web dashboard with around twenty visualisations covering usage patterns, token consumption, cost breakdowns, and project-level activity.
brew tap cross-entropy-ai/tap && brew install vibe-usage
vibe-usage sync
vibe-usage serve
Why local-first
The obvious way to build usage analytics is to collect everything centrally and serve dashboards from the cloud. We didn’t do that.
Your AI coding sessions encode your work patterns, your projects, your prompts, your mistakes. This is not telemetry you want leaving your machine. The whole point of tools like Claude Code is that they run locally, with access to your files. An analytics layer that ships this data to someone else’s server breaks the trust model.
vibe-usage stores everything under ~/.vibe-usage. You can sync between your own machines with rsync. The data doesn’t touch a server you don’t control.
What you learn
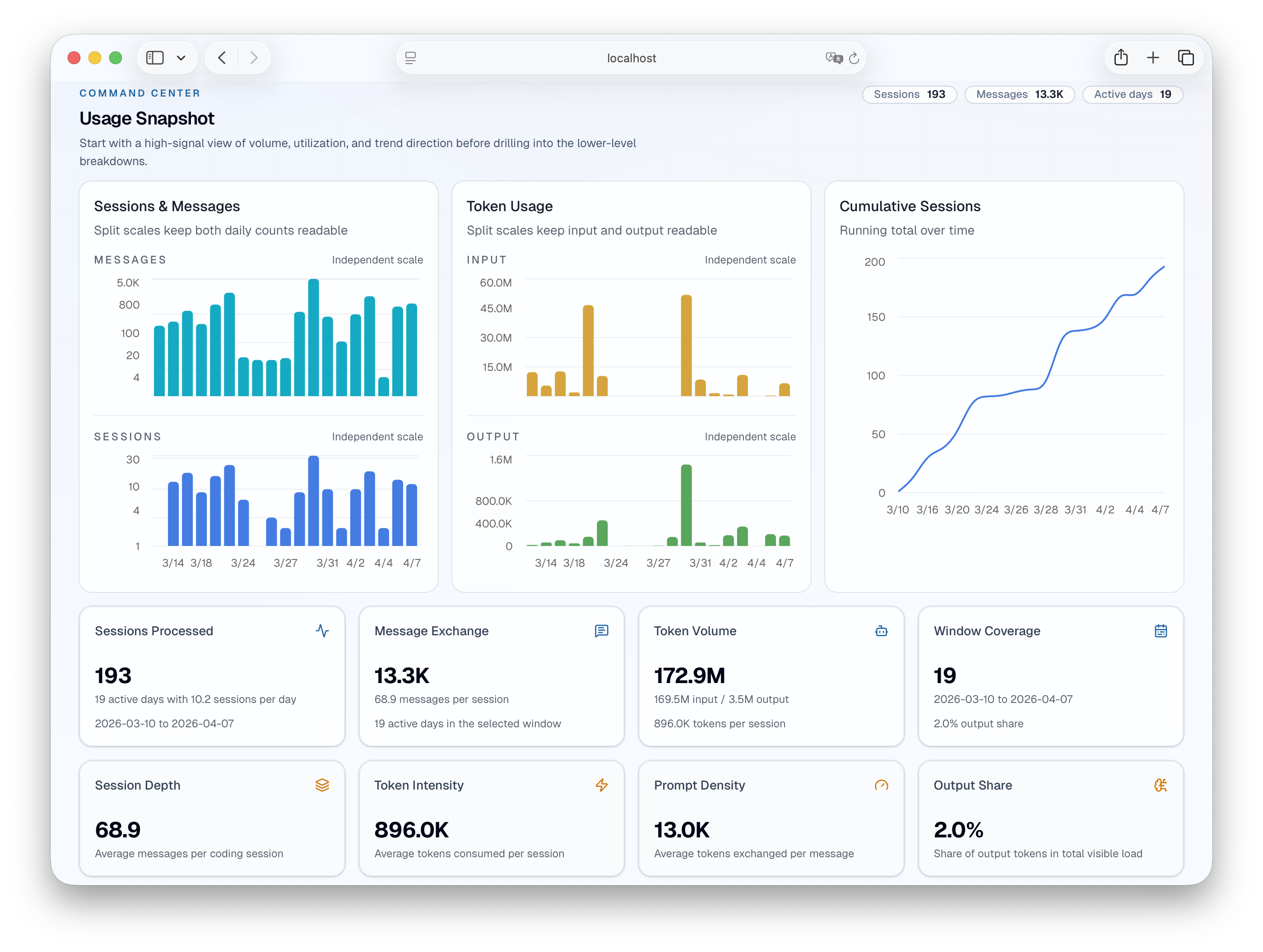
You find out which tools you really use. Stated preferences (“I mostly use Claude”) often don’t match reality. You might reach for one tool when exploring and another when implementing, and that pattern itself is worth noticing.
Token consumption is lumpy. A handful of sessions eat most of your budget. Knowing which projects and interaction patterns drive that helps you decide when to lean on AI and when to work differently.
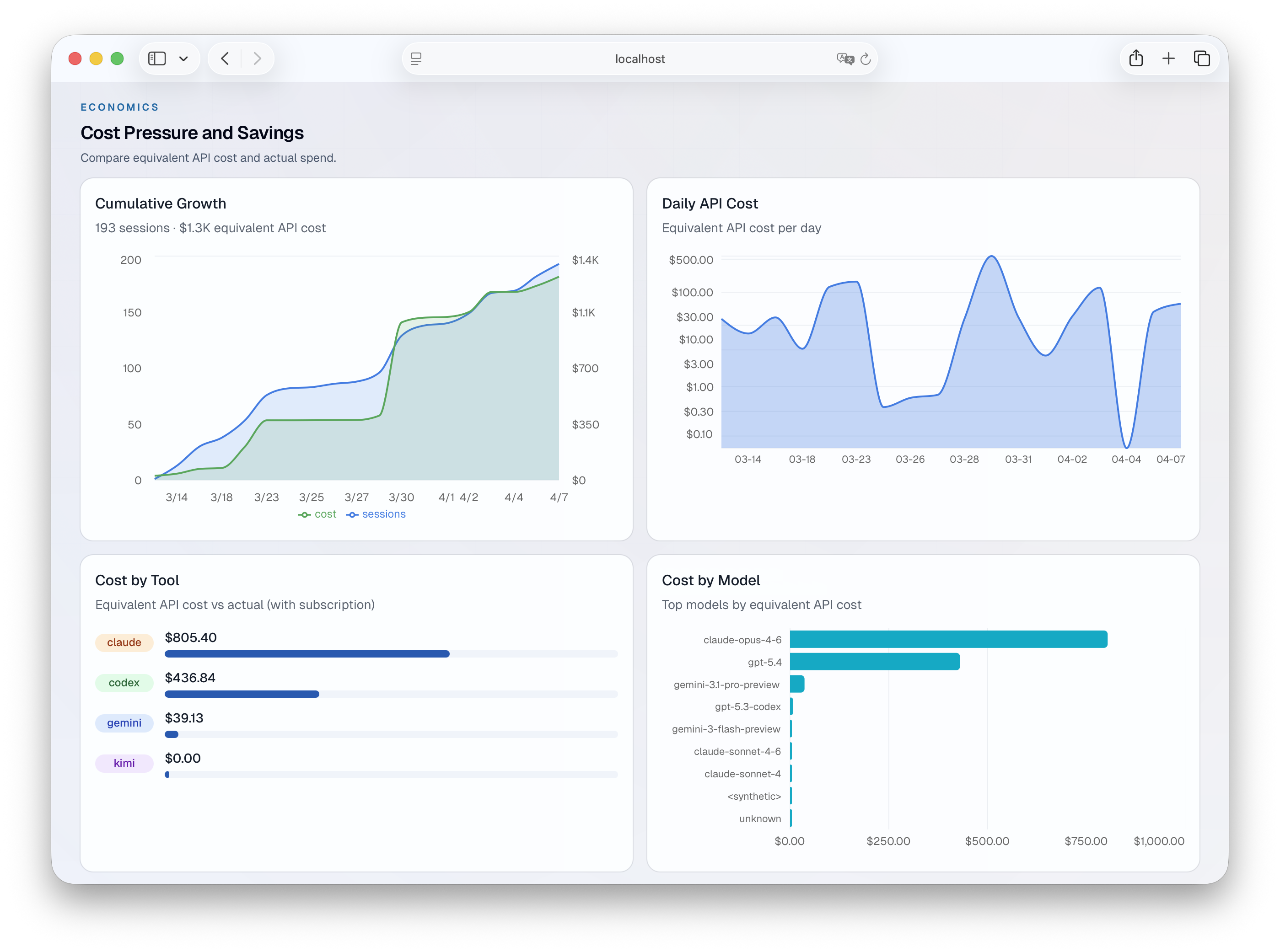
The cost view tracks cumulative API-equivalent spend, broken down by day, tool, and model. If you’re on a subscription, you see immediately what that same usage would cost at API prices.
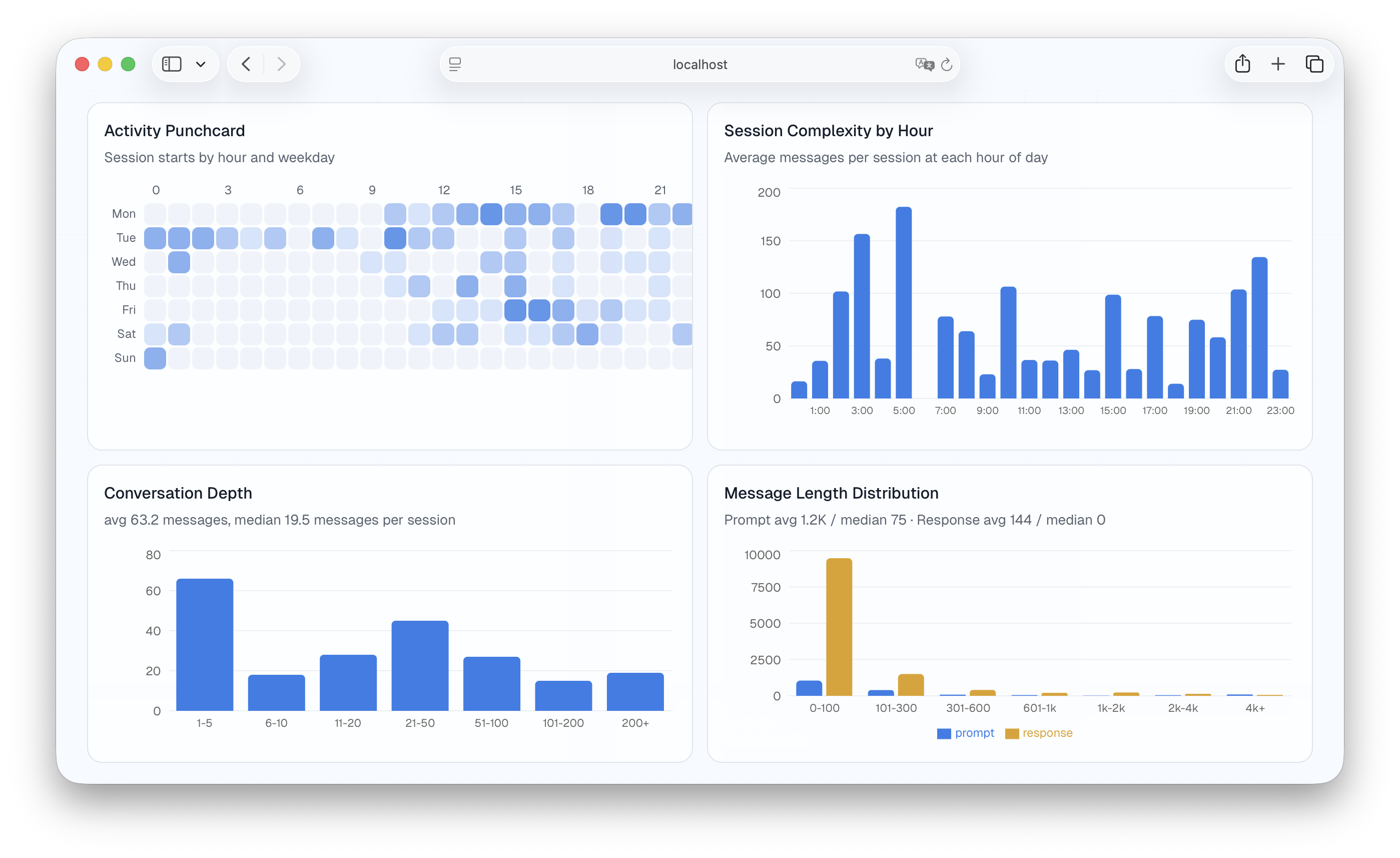
What’s next
Right now vibe-usage shows you data. The next step is to tell you something about it.
We’re working on a layer that reads your session history and produces actual analysis. A few directions we’re exploring:
Prompt pattern recognition. Most people fall into prompting habits they don’t notice. Surfacing these patterns lets you see your defaults and decide which ones are worth keeping.
Prompt skill assessment. Given enough session data, we can estimate how efficiently you use AI tools — where you’re improving and where you’re plateauing.
Failure mode detection. Some sessions burn tokens without converging. If we can spot the signatures early (repeated tool calls, escalating context, circular edits), we can flag it before the bill does.
Cross-tool comparison. Not a generic benchmark, but a personal one: for your projects, with your prompting style, which tool gets there in fewer tokens?
Session cost prediction. Before you start a task, estimate what it will likely cost based on similar past sessions.
Try it
vibe-usage is open source and available now. Install it, look at your data, tell us what you find. We’re curious about the surprises, the gap between what you thought you were doing with AI tools and what the numbers say.
That gap is, if you want to be precise about it, a kind of cross-entropy.